Dynamic Robots Exclusion File in ASP.NET
17 Jun 2013
Prevent search engines from indexing the non-production versions of your web application
Many websites have multiple versions: development, testing, staging, and production. To prevent search engines from indexing the non-production versions, you can enable username and password authentication. This is a sensible measure that not only blocks search engines from crawling your development content, but also protects it from unauthorized access.
However, you may face a problem when your client wants to test that social media sharing function on your staging website.
If you ask your IT administrator to “temporarily” disable the security, you may expose the link to the World Wide Web and allow the search engines to index your website. You may think that you can just remind yourself to ask the IT administrator to re-enable the security later. But people forget and these things do slip through with unwanted consequences, such as diluted search engine rankings, duplicate content issues, and real users making e-commerce purchases on staging!
Prevalence of Unfinished Websites on Google Search Results
Unfinished websites are web pages that are in development, test, uat, or staging phases and are not ready for public viewing. They may contain incomplete, outdated, or inaccurate information, or they may have technical issues such as broken links, errors, or malware. Unfinished websites can negatively affect your online reputation, user experience, and search rankings. The following links can reveal the number of unfinished websites appear in Google Search results:
https://www.google.com/search?q=site:dev.*
https://www.google.com/search?q=site:test.*
https://www.google.com/search?q=site:uat.*
https://www.google.com/search?q=site:staging.*
How to prevent search engines from indexing your non-production websites?
There are different ways to prevent search engines from indexing your website, depending on your needs and preferences. Based on web search results, some of the common methods are:
- Using a meta noindex tag on the pages you want to hide from search engines. This tag tells search engines not to index or show the page in their results
- Using an X-Robots-Tag HTTP header with a value of noindex or none in your response. This header can be used for non-HTML resources, such as PDFs, video files, and image files. Read our article on applying this header value server wide.
- Using a robots.txt file to block search engines from crawling certain parts of your site. However, this method is not very reliable or secure, as some search engines might ignore it or still show the page in their results.
Dynamic Robots.txt
A robots.txt file tells search engine crawlers what they can or cannot crawl on your website. The goal is to allow the search bots to crawl everything in your production website and nothing in your non-production websites.
Create two plain (ANSI encoded) text files. We are using ANSI because some web crawlers might not support UTF-8 encoding or might get confused by the BOM and ignore the contents.
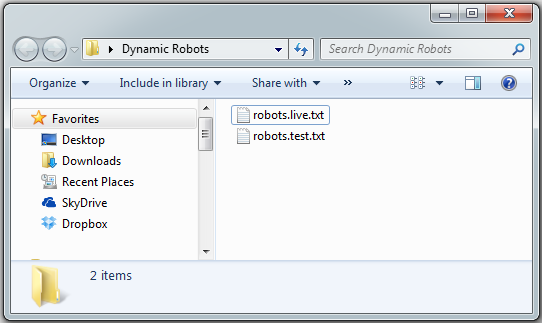
Edit <strong>robots.test.txt</strong> and add the following code:
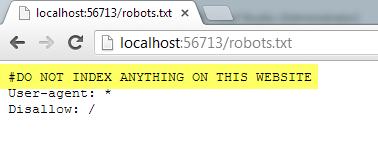
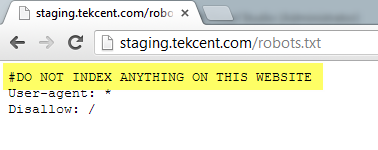
#DO NOT INDEX ANYTHING ON THIS WEBSITE
User-agent: *
Disallow: /
Edit <strong>robots.live.txt</strong> and add the following code:
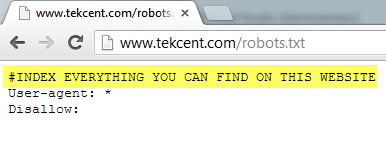
#INDEX EVERYTHING YOU CAN FIND ON THIS WEBSITE
User-agent: *
Disallow:
Did you spot the subtle difference between allowing and disallowing crawler access? The "Disallow: " (without the forward slash) allows access to all directories. Get this wrong and your whole website will drop out of the search engine index! Take note.
Next, copy the files to your website folder
At this point it's probably worth checking if you have the IIS URL Rewriting module installed on the server.
Copy the following IIS rewriting rules to the web.config system.webServer section:
<rewrite>
<rules>
<rule name="Rewrite LIVE robots.txt" enabled="true" stopProcessing="true">
<match url="robots.txt" />
<action type="Rewrite" url="/robots.live.txt" />
<conditions>
<add input="{HTTP_HOST}" pattern="^(www.)?tekcent.com" />
</conditions>
</rule>
<rule name="Rewrite TEST robots.txt" enabled="true" stopProcessing="true">
<match url="robots.txt" />
<action type="Rewrite" url="/robots.test.txt" />
<conditions>
<add input="{HTTP_HOST}" pattern="^(www.)?tekcent.com" negate="true" />
</conditions>
</rule>
</rules>
</rewrite>
Verify the results
After deploying the changes we can test the different versions of our website. Finally, this useful online tool can check the validity of your robots.txt files.